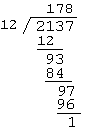| Objectives: To introduce the concept of binary notation and to demonstrate how arithmetic is performed on a digital computer. |
Topics covered:
There are four important number systems which you should become familiar with. These are decimal, binary, octal and hexadecimal. The decimal system, which is the one you are most familiar with, utilizes ten symbols to represent each digit. These are 0, 1, 2, 3, 4, 5, 6, 7, 8 and 9. This system is referred to as base 10, or radix 10 system. Similarly, the binary system is base 2, octal is base 8, and hexadecimal is base 16 as shown in Table 1.1.
| Number System |
Radix |
Symbols |
| Binary |
2 |
0 1 |
| Octal |
8 |
0 1 2 3 4 5 6 7 |
| Decimal |
10 |
0 1 2 3 4 5 6 7 8 9 |
| Hexadecimal |
16 |
0 1 2 3 4 5 6 7 8 9 A B C D E F |
Table 1.2 below shows an example of counting from 0 to 18 in each of the four number systems.
|
Radix |
Decimal |
Binary |
Octal |
Hexadecimal |
|
|
0 |
0000 |
0 |
0 |
|
|
1 |
0001 |
1 |
1 |
|
|
2 |
0010 |
2 |
2 |
|
|
3 |
0011 |
3 |
3 |
|
|
4 |
0100 |
4 |
4 |
|
|
5 |
0101 |
5 |
5 |
|
|
6 |
0110 |
6 |
6 |
|
|
7 |
0111 |
7 |
7 |
|
|
8 |
1000 |
10 |
8 |
|
|
9 |
1001 |
11 |
9 |
|
|
10 |
1010 |
12 |
A |
|
|
11 |
1011 |
13 |
B |
|
|
12 |
1100 |
14 |
C |
|
|
13 |
1101 |
15 |
D |
|
|
14 |
1110 |
16 |
E |
|
|
15 |
1111 |
17 |
F |
|
|
16 |
10000 |
20 |
10 |
|
|
17 |
10001 |
21 |
11 |
|
|
18 |
10010 |
22 |
12 |
| In computer systems, the number or value of zero is frequently encountered. It is incorrect to refer to this as "nothing" since this term will be reserved to mean "no information". In fact, the value 0 conveys as much information as the value 1. Therefore, throughout this course, the value 0, an all-zeros pattern, 0 volts, or a constant voltage level must never be referred to as "nothing". |
Working in binary can become very cumbersome and prone to errors. It is important to learn how to convert from one system to another. Let us take the binary pattern 1011101 as an example. If we are working predominantly in the octal system, we would break this into groups of three bits, starting from the right.
1011101 = 1 011 101 = 1358
The subscript 8 is used to indicate that it is the octal representation. After converting to octal, the conversion to base 10 is simplified.
Mathematically, the decimal value can be computed as (1 × 82) + (3 × 81) + (5 × 80) = 93. However, in a computer program it would be more efficient to use an iterative algorithm. Thus the result is computed as:
((1 × 8) + 3) × 8 + 5 = 93.
Here is the algorithm
Step 1: Start with the result equal to the left-most symbol.
Step 2: If this is not the right-most symbol, multiply the result by the radix.
Step 3: Add the next symbol to the result.
Step 4: Repeat steps 2 and 3 if there are still more symbols to the right.
For example, to convert 1358 to decimal,
Start with Result = 1
Result = 1 × 8 = 8
Result = 8 + 3 = 11
Result = 11 × 8 = 88
Result = 88 + 5 = 93
Thus the final result of the conversion is 1 011 1012 = 1358 = 9310
Now, let us assume that we are working predominantly with the hexadecimal system, as is the convention on most microcomputers. In this case, we split the binary pattern into groups of four bits as follows:
010111012 = 0101 1101 = 5D16
The conversion to decimal proceeds in a similar manner as before.
5D16 = (5 x 16) + 13 = 93
The result is: 010111012 = 5D16 = 9310
Note that this result agrees with the previous conversion to octal.
| The symbols $ and h are commonly used to signify hexadecimal notation, for example, $5D or 5Dh. |
Converting an octal or hexadecimal number to its binary representation is straight forward. For example:
3618 = 011 110 0012
1A416 = 0001 1010 01002
Converting a decimal number to its binary representation is slightly more complex. It is simplified if you convert the decimal number to its octal or hexadecimal equivalent first. For example, let us find the binary representation of 144910. First, we shall convert it to its octal representation.
Algorithm
Step 1: Divide the decimal number by the new radix and save the remainder.
Step 2: Repeat step 1 until the quotient is 0.
Example
1449 ÷ 8 = 181, remainder = 1
181 ÷ 8 = 22, remainder = 5
22 ÷ 8 = 2, remainder = 6
2 ÷ 8 = 0, remainder = 2
Thus, 144910 = 26518 = 010 110 101 0012
| As an exercise, convert 1449 to hexadecimal first and then to binary. Then work backwards from octal and hexadecimal and verify that you end up with the original decimal value. |
The native language of digital computers is inherently binary. Thus, numbers are naturally represented as binary integers by the computer. The range of numbers which can be represented is dependent on the number of bits used. A common unit of storage is a byte which is a group of eight bits. Eight bits can represent 28 unique states, i.e. 256 possible combinations. This fact can be used to our advantage to represent many different things on the computer. For example, a byte can be used to represent 256 colours, 256 shades of grey, 256 shapes, 256 symbols, 256 names, or even 256 different numbers. More typically, we can use a byte to represent 256 sequential numbers such as the numbers from 1 to 256, or the numbers from 0 to 255. Remember that 0 is not "nothing" and has equal significance as any other number.
As another example, how about the numbers from -128 to 127? Note that there are 256 unique numbers in this range. Count them all! If we use a system whereby $00 represents -128 and $FF represents +127, we have created a number system called biased or offset binary, since the sequence of numbers represented is offset by a constant.
Another scheme is to reserve one of the eight bits to indicate the sign of the number. Following usual convention, the left-most bit (called the most significant bit or MSB) is dedicated as the sign bit. With this scheme, we can now have 128 positive and 128 negative numbers, typically the numbers from 0 to 127. This scheme has the anomaly that there are two unique representations for positive and negative zero. A more serious problem is that the rules of binary arithmetic breakdown when we decrement by 1 from positive to negative numbers. To overcome the discontinuity at zero, a scheme of complementary binary is used whereby negative numbers are represented by the binary complement of the positive representation. This system is called one's complement binary. This system also has two unique representations for positive and negative zero.
The two's complement binary system overcomes both problems mentioned above. In this notation, the negative number is represented by forming the binary complement of the positive number and adding one. Table 1.3 shows how different numbers are represented by the different systems. Note that in all the signed binary systems discussed, the sign is represented by the MSB.
|
Decimal |
Unsigned |
Offset |
Signed |
1's Complement |
2's Complement |
|
255 |
377 |
||||
|
254 |
376 |
||||
|
:: |
:: |
||||
|
127 |
177 |
377 |
177 |
177 |
177 |
|
126 |
176 |
376 |
176 |
176 |
176 |
|
:: |
:: |
:: |
:: |
:: |
:: |
|
1 |
001 |
201 |
001 |
001 |
001 |
|
0 |
000 |
200 |
000 |
000 |
000 |
|
-0 |
NA |
200 |
377 |
NA |
|
|
-1 |
177 |
201 |
376 |
377 |
|
|
-2 |
176 |
202 |
375 |
376 |
|
|
:: |
:: |
:: |
:: |
:: |
|
|
-127 |
001 |
376 |
200 |
201 |
|
|
-128 |
000 |
377 |
200 |
All numbers are in octal notation except for the first column which is in decimal. NA stands for not available.
To summarize, integers are commonly represented by the unsigned binary and the 2's complement binary
representations. The range of integer numbers can be extended by utilizing more bits. For example, 16 bits will
allow us to represent 216 unique items, i.e. 65536 possible states. These can be the numbers from 0
to 65535 for unsigned integers or -32768 to 32767 for 2's complement signed integers.
It is useful to know the value of 2 raised to the power n, for n = 1 to 16. Table 1.4 shows 2n , for n = 0 to 32.
|
n |
2n |
n |
2n |
|
0 |
1 |
||
|
1 |
2 |
17 |
131 072 |
|
2 |
4 |
18 |
262 144 |
|
3 |
8 |
19 |
524 288 |
|
4 |
16 |
20 |
1 048 576 |
|
5 |
32 |
21 |
2 097 152 |
|
6 |
64 |
22 |
4 194 304 |
|
7 |
128 |
23 |
8 388 608 |
|
8 |
256 |
24 |
16 777 216 |
|
9 |
512 |
25 |
33 554 432 |
|
10 |
1 024 |
26 |
67 108 864 |
|
11 |
2 048 |
27 |
134 217 728 |
|
12 |
4 096 |
28 |
268 435 456 |
|
13 |
8 192 |
29 |
536 870 912 |
|
14 |
16 384 |
30 |
1 073 741 824 |
|
15 |
32 768 |
31 |
2 147 483 648 |
|
16 |
65 536 |
32 |
4 294 967 296 |
This table shows that a 16-bit addressing scheme on a computer is limited to 64K memory addresses, while a 24-bit system provides access to 16M memory addresses. A 32-bit system allows access to 4G memory addresses. Note that in computer terminology, the following units are used, where K stands for kilo, M is mega and G is giga.
210 = 1K = 1 024
220 = 1M = 1 048 576
230 = 1G = 1 073 741 824
To help you memorize the important powers of 2, reflect on the following:
24 = 16
28 = (16)2 = 256
210 = 1K = 1 024
212 = 1K × 22 = 4 096
216 = 1K × 26 = 65 536
220 = (1K)2 = 1M = 1 048 576
The decimal point is used to separate the integral (whole) and fractional parts of a number. For example, 123.4 can be considered as 123 plus 4/10. This is more formally defined as:
1 × 102 + 2 × 101 + 3 × 100 + 4 × 10-1
Binary fractions are defined using the same conventions. For example, 101.112 can be considered to be 5 plus 1/2 plus 1/4, or
1 × 22 + 0 × 21 + 1 × 20 + 1 × 2-1 + 1 × 2-2
Let us examine a case where two bytes are used to store a fractional number and where the most significant byte is the integer part and the least significant byte is the fractional part. For example, 0001 0111.1000 0001 would represent the value
1 × 161 + 7 × 160 + 8 × 16-1 + 1 × 16-2 = 23 + 1/2 + 1/256 = 23.500390625
Note the following interesting observations. Even though it takes a substantial number of digits to write down the equivalent decimal value, the actual range of values that can be represented is still limited to approximately -128 to + 128. Secondly, the smallest incremental step between two values (the resolution or precision) is limited to 1/256 or 0.00390625. The dynamic range is the range of unsigned values from the smallest to the largest that can be represented. In this case, the dynamic range is from 1/256 to 128. Thirdly, there are many decimal numbers which cannot be represented exactly, 0.1 for example, and this could lead to rounding errors in arithemetic.
How is the decimal point stored on the computer? You may think that the decimal point is stored as a character byte but this would be a waste of precious 8 bits. The decimal point occupies no storage space and therefore its position must be implied. In other words, the programmer must establish beforehand where the decimal point is to be placed. This is called fixed point representation. With 16 bits used to represent our number, we can arbitrarily assign any number of bits for the integer part and the remaining bits to the fractional part. In this way we compromise precision for dynamic range, or vice versa, depending on the specific application.
Real numbers refer to the continuum of values from -infinity to +infinity. Since storage on the computer is limited, one has to compromise between the dynamic range and precision, as already pointed out above. But rather than having a fixed number of bits assigned to the integral and fractional parts as in fixed point notation we can create a system that automatically optimizes the position of the decimal point in order to preserve the most significant information in the number. For example, suppose we need to represent the numbers 0.000123 and 123000. Since there is no good reason to carrying around the extra zeros, we could write these numbers as 1.23 x 10-4 and 1.23 x 105 respectively, using standard scientific notation. Now all we need to record is the significant part called the mantissa and the exponent. This system is called floating point representation.
There is an infinite number of ways to represent a real number in floating point representation and many different conventions are in use today. The precision is dependent on the number of bits used to represent the mantissa while the dynamic range is dependent on the number of bits assigned to the exponent. Let us examine the standard IEEE (Institute of Electrical and Electronic Engineers) representation for short real numbers. The IEEE representation (IEEE Std 754-1985) for short real numbers uses 4 bytes, i.e. 32 bits as shown below, where 23 bits are assigned to the mantissa while the exponent is a signed 8-bit value.
|
SIGN |
EXPONENT |
MANTISSA |
||||
|
31 |
30 |
23 |
22 |
0 |
||
The value V of the number is determined by
V = (-1)S × 2(E-127) × (1.M)
where S is the value of the sign bit, E is the value of the exponent field and M is the mantissa.
The sign is represented by a single bit, which is 0 for positive numbers and 1 for negative numbers. The exponent is an 8-bit field which represents the signed power to which base 2 is raised. The system used for this exponent is biased binary such that 011111112 represents 2 raised to the power 0. The mantissa is the unsigned binary representation of a fraction between 0 and 1. The dynamic range for short real numbers is 1 × 10-45 to 3 × 1038. Here are some simple examples:
$3F000000 = 0.5
$3F800000 = 1.0
$40000000 = 2.0
$40A00000 = 5.0
All floating point numbers in the IEEE format must be normalized. This is the process whereby the mantissa is shifted to the left (i.e. multiplied by the base 2) until the MSB (most significant bit) of the mantissa is 1. The exponent is corrected to reflect this adjustment. By performing this normalization, the mantissa is used to its fullest and thus the number is stored at a maximum precision. Writing the number in the binary form 1.XXXXXX x 2n automatically performs the normalization. Doing this would imply that the MSB of the mantissa must always be a 1 and therefore need not be stored. This "1" is known as the hidden bit. Since the hidden bit takes up no storage space, we gain one extra bit of precision.
While floating-point arithmetic provides some advantages over integer arithmetic, it also comes with many pitfalls. The first drawback is speed and efficiency. There is about a 1000:1 penalty in computer time and storage requirements when using floating-point arithmetic unless you have a math coprocessor at your disposal. In fact, there are many practical situations when the use of floating-point arithmetic, whether performed by software or hardware, is both unnecessary and overkill.
| Problem: You are required to design a handheld clinical thermometer that displays temperature readings in both °C and °F with a resolution of 0.1 degrees. Devise an algorithm for converting temperatures from °C to °F using only integer addition and logical shift left operations. |
Even worse, floating-point arithmetic can introduce unforeseen errors in calculations as a result of rounding errors. This is because most numbers cannot be represented exactly by the floating-point formats. For example, we all know that 1/3 has no exact representation, and so does 0.1. Try calculating (1000.2 - 1000) on a computer. Is your result 0.2 as expected?
Pay particular attention to computations involving:
There are many situations in scientific research where information is extracted from a signal by subtracting a background or baseline measurement, for examples, gamma-ray spectroscopy, densitometry. Signal averaging, a technique used to extract a signal buried in noise, requires summing nearly equal values whose signs may be opposite. In each of these examples, floating-point calculations may produce undesirable errors.
The rules for binary integer arithmetic follow the same rules as for decimal numbers. Bear in mind that on a digital computer the place holders for numbers (called accumulators or registers) are implemented in hardware of fixed word lengths. Thus arithmetic that produces results that exceed the size of the register will produce overflows and unexpected or erroneous results. As a simple example, suppose that the accumulator is a 4-bit register, then adding 12 and 6 would give the following results for unsigned binary addition:
|
Binary |
Decimal |
|
|
1100 |
12 |
|
|
+ |
0110 |
6 |
|
0010 |
2 |
That is, the result is always modulus 16.
For signed binary addition, the sum of 6 and 3 would give:
|
Binary |
Decimal |
|
|
0110 |
6 |
|
|
+ |
0011 |
3 |
|
1001 |
-7 |
Note that in either case this is not a computer error. It is our expectation and interpretation of the results that may be flawed. Flaws of this nature are what we may loosely call computer bugs.
In a digital computer, arithmetic is performed using special hardware called the Arithmetic/Logic Unit (ALU).
The simplest operations are addition and 1's complement. With only these two functions, other operations such as
subtraction and multiplication are possible. Recall that the 2's complement is created by forming the 1's complement
and adding a 1. Subtraction, whether implemented in hardware or software, is performed by first forming the 2's
complement of the second argument and then adding it to the first argument.
Usually, two other logic functions, left shift and right shift, are provided since these are also easy to implement in hardware. When a number is shifted by one digit to the left, for example, 123 left shifted becomes 1230, this is equivalent to multiplying the number by the radix, whatever it may be. Similarly, 123 shifted to the right is 12.3 and this is the same as dividing by the radix. In binary, shifting left by one bit is equivalent to multiplying by 2. Shifting right by one bit is the same as dividing by 2.
Let us review how one would multiply two decimal numbers. Suppose we wish to find 2941 x 318. The first number
is called the multiplicand and the second is the multiplier. There are two ways of doing this depending
on which end of the multiplier we begin with. The following should look familiar:
|
2941 |
|
|
× 318 |
|
|
2941 × 8 = |
23528 |
|
29410 × 1 = |
29410 |
|
294100 × 3 = |
882300 |
|
935238 |
|
2941 × 3 = |
8823 |
× 100 = |
882300 |
|
2941 × 1 = |
2941 |
×10 = |
29410 |
|
2941 × 8 = |
23528 |
× 1 = |
23528 |
|
935238 |
In both cases, the product can be formally stated as the sum of partial products as follows:
2941 × 318 = (2941 × 3 × 102 ) + (2941 × 1 × 101 ) + (2941 × 8 × 100 )
Multiplication in binary (or any other radix) can be performed using the same technique as for decimal. Both methods
shown are easily implemented in binary on a digital computer. In the examples shown above, the partial products
are first formed and the summation is done at the end. In a computer algorithm this is not the usual case since
it is more efficient to sum the partial products as they are formed. In special processors optimized for speed,
such as digital signal processors (DSP), dedicated hardware to do this is called a multiply and accumulate
register (MAC). Let us create algorithms for the two methods shown above.
Method 1
Step 1. Begin with the result set to zero.
Step 2. Extract the rightmost digit of the multiplier (by dividing by the radix) and multiply with the multiplicand.
Step 3. Add this partial product to the result.
Step 4. Shift the multiplicand to the left (by multiplying by the radix).
Step 5. Repeat Steps 2 to 4 until the multiplier is zero.
Method 2
Step 1. Begin with the result set to zero.
Step 2. Extract the leftmost digit of the multiplier(by multiplying by the radix) and multiply with the multiplicand.
Step 3. Add this partial product to the result.
Step 4. If this is not the last digit, multiply the result by the radix.
Step 5. Repeat Steps 2 to 4 until no digits remain in the multiplier.
In Method 1, we shift the multiplier to the right to extract the LSB (least significant bit or digit), multiply
and accumulate, and then shift the multiplicand to the left. In Method 2, we shift the multiplier to the left to
extract the MSB, multiply and accumualte, and then shift the result to the left only if there are more digits remaining
in the multiplier.
Multiplying in binary follows the same rules. Suppose we wish to find 111 x 101. This can be formulated as follows:
(111 × 1 × 22 ) + (111 × 0 × 21 ) + (111 × 1 × 20 )
With binary arithmetic, the task of multiplying by 2 is simply a shift of one bit to the left. Similarly, dividing by 2 is a shift of one bit to the right. Furthermore, in forming the partial products, there are only two possible multipliers, 0 or 1, and the multiplication is a trival matter. A multiplier of 0 or 1 simply determines whether or not the multiplicand is added to the accumulated sum.
In division, the dividend (or numerator) is divided by the divisor (or denominator) to produce the quotient and remainder. Suppose we wish to find 2137 ÷ 12 by the process of long division.
That is, 2137 ÷ 12 = 178, with a remainder of 1.
Method of long division.
Step 1. Working from the left of the dividend, left shift and extract the first value that is greater or equal to the divisor.
Step 2. Subtract the highest multiple of the divisor which is less than or equal to the extracted value and record the multiplier in the quotient field.
Step 3. Bring down the next digit (i.e. left shift the dividend).
Step 4. Repeat steps 2 and 3 until the remainer is less than the divisor.
Division in binary follows the same concept as for long division in decimal. We begin with a register set to zero
and left shift the dividend into it until the value in the register is equal to or greater than the divisor. The
quotient field is also left shifted each time. Binary division is simplified by the fact that there will be only
two multiples of the divisor, that is, ×0 and ×1, which will be subtracted from the register. Hence
the partial quotient can only be 0 or 1. Of course, multiplication by 0 and 1 is a trivial matter.